信息论入门教程
1948年,美国数学家克劳德·香农发表论文《通信的数学理论》(A Mathematical Theory of Communication),奠定了信息论的基础。
{kind=link}
今天,信息论在信号处理、数据压缩、自然语言等许多领域,起着关键作用。虽然,它的数学形式很复杂,但是核心思想非常简单,只需要中学数学就能理解。
本文使用一个最简单的例子,帮助大家理解信息论。
一、词汇的编码
小张是我的好朋友,最近去了美国。
{kind=link}
我们保持着邮件联系。小张写信的时候,只使用4个词汇:狗,猫,鱼,鸟。
{kind=link}
信的所有内容就是这4个词的组合。第一封信写着"狗猫鱼鸟",第二封信写"鱼猫鸟狗"。
信件需要二进制编码,在互联网传递。两个二进制位就可以表示四个词汇。
- 狗 00
- 猫 01
- 鱼 10
- 鸟 11
所以,第一封信"狗猫鱼鸟"的编码是00011011,第二封信"鱼猫鸟狗"的编码是10011100。
二、词汇的分布
最近,小张开始养狗,信里提到狗的次数,多于其他词汇。假定概率分布如下。
- 狗:50%
- 猫:25%
- 鱼:12.5%
- 鸟:12.5%
小张的最新一封信是这样的。
狗狗狗狗猫猫鱼鸟
上面这封信,用前一节的方法进行编码。
0000000001011011
一共需要16个二进制。互联网的流量费很贵,有没有可能找到一种更短编码方式?
很容易想到,"狗"的出现次数最多,给它分配更短的编码,就能减少总的长度。请看下面的编码方式。
- 狗 0
- 猫 10
- 鱼 110
- 鸟 111
使用新的编码方式,小张的信"狗狗狗狗猫猫鱼鸟"编码如下。
00001010110111
这时只需要14个二进制位,相当于把原来的编码压缩了12.5%。
根据新的编码,每个词只需要1.75个二进制位(14 / 8)。可以证明,这是最短的编码方式,不可能找到更短的编码,详见后文。
三、编码方式的唯一性
前一节的编码方式,狗的编码是0,这里的问题是,可以把这个编码改成1吗,即下面的编码可行吗?
- 狗 1
- 猫 10
- 鱼 110
- 鸟 111
回答是否定的。如果狗的编码是1,会造成无法解码,即解码结果不唯一。110有可能是"狗猫",也可能是"鱼"。只有"狗"为0,才不会造成歧义。
下面是数学证明。一个二进制位有两种可能0和1,如果某个事件有多于两种的结果(比如本例是四种可能),就只能让0或1其中一个拥有特殊含义,另一个必须空出来,保证能够唯一解码。比如,0表示狗,1就必须空出来,不能有特殊含义。
同理,两个二进制位可以表示四种可能:00、01、10和11。上例中,0开头的编码不能用了,只剩下10和11可用,用10表示猫,为了表示"鱼"和"鸟",必须将11空出来,使用三个二进制位表示。
这就是,上一节的编码方式是如何产生的。
四、编码与概率的关系
根据前面的讨论,可以得到一个结论:概率越大,所需要的二进制位越少。
- 狗的概率是50%,表示每两个词汇里面,就有一个是狗,因此单独分配给它1个二进制位。
- 猫的概率是25%,分配给它两个二进制位。
- 鱼和鸟的概率是12.5%,分配给它们三个二进制位。
香农给出了一个数学公式。L表示所需要的二进制位,p(x)表示发生的概率,它们的关系如下。
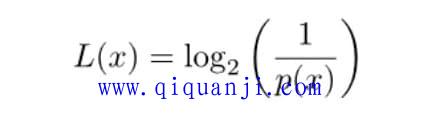{kind=link}
通过上面的公式,可以计算出某种概率的结果所需要的二进制位。举例来说,"鱼"的概率是0.125,它的倒数为8, 以 2 为底的对数就是3,表示需要3个二进制位。
知道了每种概率对应的编码长度,就可以计算出一种概率分布的平均编码长度。
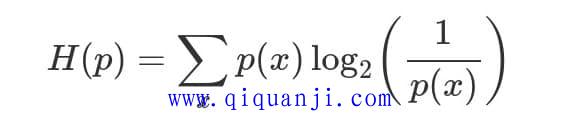{kind=link}
上面公式的H,就是该种概率分布的平均编码长度。理论上,这也是最优编码长度,不可能获得比它更短的编码了。
接着上面的例子,看看这个公式怎么用。小张养狗之前,"狗猫鱼鸟"是均匀分布,每个词平均需要2个二进制位。
H = 0.25 x 2 + 0.25 x 2 + 0.25 x 2 + 0.25 x 2
= 2
养狗之后,"狗猫鱼鸟"不是均匀分布,每个词平均需要1.75个二进制位。
H = 0.5 x 1 + 0.25 x 2 + 0.125 x 3 + 0.125 x 3
= 1.75
既然每个词是 1.75 个二进制位,"狗狗狗狗猫猫鱼鸟"这8个词的句子,总共需要14个二进制位(8 x 1.75)。
五、信息与压缩
很显然,不均匀分布时,某个词出现的概率越高,编码长度就会越短。
从信息的角度看,如果信息内容存在大量冗余,重复内容越多,可以压缩的余地就越大。日常生活的经验也是如此,一篇文章翻来覆去都是讲同样的内容,摘要就会很短。反倒是,每句话意思都不一样的文章,很难提炼出摘要。
图片也是如此,单调的图片有好的压缩效果,细节丰富的图片很难压缩。
由于信息量的多少与概率分布相关,所以在信息论里面,信息被定义成不确定性的相关概念:概率分布越分散,不确定性越高,信息量越大;反之,信息量越小。
六、信息熵
前面公式里的H(平均编码长度),其实就是信息量的度量。H越大,表示需要的二进制位越多,即可能发生的结果越多,不确定性越高。
比如,H为1,表示只需要一个二进制位,就能表示所有可能性,那就只可能有两种结果。如果H为6,六个二进制位表示有64种可能性,不确定性大大提高。
信息论借鉴了物理学,将H称为"信息熵"(information entropy)。在物理学里,熵表示无序,越无序的状态,熵越高。
七、信息量的实例
最后,来看一个例子。如果一个人的词汇量为10万,意味着每个词有10万种可能,均匀分布时,每个词需要 16.61 个二进制位。
log₂(100, 000) = 16.61
所以,一篇1000个词的文章,需要 1.6 万个二进制位(约为 2KB)。
16.61 x 1000 = 16,610
相比之下,一张 480 x 640、16级灰度的图片,需要123万个二进制位(约为 150KB)。
480 x 640 x log₂(16) = 1,228,800
所以,一幅图片所能传递的信息远远超过文字,这就是"一图胜千言"吧。
上面的例子是均匀分布的情况,现实生活中,一般都是不均匀分布,因此文章或图片的实际文件大小都是可以大大压缩的。
八、参考链接
- Visual Information Theory, by Christopher Olah
- Information Theory (PDF), Roni Rosenfeld
本站声明:网站内容来源于网络,如有侵权,请联系我们https://www.qiquanji.com,我们将及时处理。
微信扫码关注
更新实时通知