字符串匹配算法
问题描述
字符串匹配问题可以归纳为如下的问题:
在长度为n的文本T[1...n]中,查找一个长度为m的模式P[1...m]。并且假设T,P中的元素都来自一个有限字母集合Ʃ。如果存在位移s,其中0≤s≤n-m,使得T[s+1..s+m] = P[1..m]。则可以认为模式P在T中出现过。
1. 朴素算法
最简单的字符串匹配算法是朴素算法。该算法最直观,通过遍历文本T,对每一个可能的位移s都比较T[s+1..s+m]于P[1..m]是否匹配。
代码实现
代码用python写的:
def naive_string_match(T, P):
n = len(T)
m = len(P)
for s in range(0, n-m+1):
k = 0
for i in range(0, m):
if T[s+i] != P[i]:
break
else:
k += 1
if k == m:
print s
算法分析
最坏情况下,对每一个s都需要做m次(模式P的长度为m)的比较。则算法的上届是O((n-m+1)*m)。到后面我们会看到朴素算法之所以慢,是因为它只是关心有效的位移,而忽略其它无效的位移。当一次位移s被验证是无效的之后,它只是向右位移1位,然后从头开始继续下一次的比较。这样做完全没有利用到之前已经匹配的信息,而这些信息有时候会很有用。
2. Rabin-Karp算法
对朴素算法的一个简单的改进就是Rabin-Karp算法。Rabin-Karp算法的思路是将字符串的比较转换成数字的比较。比较两个长度为m的字符串是否相等需要O(m)的时间,而比较两个数字是否相等通常可以是Ɵ(1)。为了将字符串映射到对应的数字,我们需要用到哈希函数。我们都知道开放寻址法的哈希函数(open addressing)是可能遇到冲突的。对于这个问题来说冲突意味着虽然两个字符串的哈希值是一样的,但是这两个字符串实际上是不一样的。解决的办法是当遇到哈希值相同时,再做m次(模式P的长度为m)遍历,近一步判断这两个字符串是否相等。既是说,哈希值是第一步地判断,如果两个字符串不相等那么他们的哈希值也肯定不相等。通过第一步的筛选后,再做近一步更可靠的筛选。运气好的话,大部分不匹配的字符串会在第一步(通过哈希值)被筛选掉,仅留有少量的字符串需要近一步的审查。
代码实现
继续附上Python代码:
def rabin_karp_matcher(T, P):
n = len(T)
m = len(P)
h1 = hash(P)
for s in range(0, n-m+1):
h2 = hash(T[s:s+m])
if h1 != h2:
continue
else:
k = 0
for i in range(0, m):
if T[s+i] != P[i]:
break
else:
k += 1
if k == m:
print s
算法分析
从代码上来看Rabin-Karp算法与朴素算法十分近似,最坏情况下,每一个哈希值都冲突,而且对每个冲突都进行了m次的比较。在这种情况下,该算法的时间复杂度与朴素算法相同,如果算上哈希算法的开销,时间复杂度还要高出朴素算法(通常一个字符串进行哈希的算法的时间复杂度是Ɵ(1))。当然这是最坏情况下的分析,对于平均情况下Rabin-Karp算法的效果要好得多。根据数学推断,Rabin-Karp算法的平均情况下的时间复杂度是O(n+m)。
详细分析
以下这一段分析Rabin-Karp的平均复杂度。如果不关心O(n+m)具体是如何得来的可以跳过这一段。
我们称两个字符串哈希值相同为一次命中,如果这两个字符串实际上是不同的则这次命中是一个伪命中。我们期望伪命中的次数要少一些,因为越少的伪命中意味着算法的效率越高。伪命中问题实际上是哈希算法的冲突问题,因此具体冲突的次数与具体的哈希算法相关。
算法导论中给出的哈希算法是:
t[s+1] = (d * (t[s]-T[s+1]) * h) + T[s+m+1]) mod q
该算法是将字符串的每一个位的字符转换成对应的数字,再根据一定的权重相乘得到一个数值,最后对q取模映射到[0, q-1]空间的一个值。有n个数字待映射到[0, q-1]这q个值中。如果一个哈希函数把一个数字随机地映射到q个数中的任意一个,理论上来说冲突的个数O(n/q)。假设正确命中的个数是v,由前面讨论伪命中的个数是n/q。那么Rabin-Karp算法的期望运行时间是:O(n)+O(m(v+n/q))。如果有效命中v=O(1)并且q≥n,那么Rabin-Karp算法的时间复杂度是O(n+m)。
Rabin-Karp算法优势
Rabin-Karp算法的优势是可以多维度或者多模式的匹配字符串。以多模式匹配为例,如果你需要在文本T中找出模式集合P=[P1, P2, ...Pk]中所有出现的模式。对于这个问题,Rabin-Karp算法的威力就能发挥出来了,Rabin-Karp算法能通过简单地扩展便能够支持多模式的匹配。
3. 利用有限状态自动机进行字符串匹配
有限状态自动机是一个处理信息的机器,通过对文本T进行扫描,找出模式P的所有出现的位置。在建立有限状态自动机后只需要对T一次扫描便可以完成所有匹配工作(即匹配时间是O(n))。但是如果字符集Ʃ很大时,建立自动机的时间消费很大,这是这种方法的缺点。虽然一开始可能会被这个有限状态自动机的名字吓到(我就是这样),因为看上去好像很高大上,但相信我,当你细看之后会发现并没有想象的那么难。
有限状态自动机定义
先给出定义,有限状态自动机M是一个5元组(Q,q0,A,Ʃ,δ),其中:
Q是状态集合。
q0属于集合Q,q0是初始状态。
A是可接收的状态集合(A是Q的子集合)。
Ʃ是字符集。
δ是一个Q×Ʃ到Q的函数,称为状态转移函数。
有限状态自动机算法工作流程
对应到我们的字符串匹配问题中,有限状态自动机的工作流程如下:开始于状态q0,每次读入输入字符串的一个字符a,则它状态从q变为状态δ(q,a)。每当其当前q> 属于A时,自动机M就接受起劲为止所读入的所有字符串。
构造自动机
为了能构造一个字符串配对的自动机,我们还需要4个定义,以方便我们后续的表达和计算。
定义1:对于模式P,Pq表示P的前q个字符组成的子串。
定义2:字符串P的前缀是{ Pi | 0≤i≤P.length }。例如“ababa”的前缀为 { “a”,”ab”,”aba”,”abab”,”ababa” }。字符串后缀定义与前缀的定义相似。
定义3:设前缀函数ơ(x)是x的后缀中在模式P中的最长前缀的个数。例如P=ab, 则ơ(ccaca)=1,ơ(ccab)=2。
定义4:字符串A、B,则AB意味着字符串A与B的链接。例如A=“aba”, B=”c”,则AB=”abac”。
好了,有了上述的定义我们就可以得到我们的字符串匹配自动机的定义。(又是定义,掩面偷笑)根据给定的字符串模式P[1...m],其字符串匹配自动机的定义如下:
状态集合Q={0,1,2...,m}。其中q0是状态0,状态m是唯一被接受的状态。对任意的状态q和字符a,转移函数δ(q,a)=ơ(Pqa)(注意:这里Pqa表示字符串Pq和字符串a的链接)。
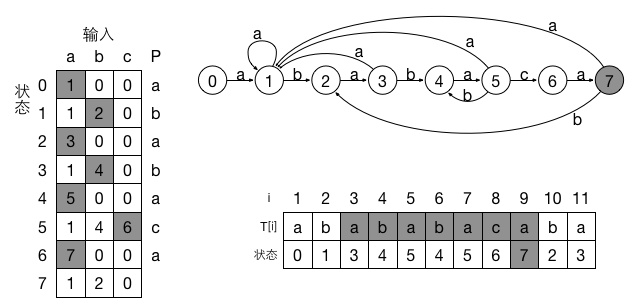{kind=link}
来看一个例子,上图是模式P=“ababaca”的字符串匹配自动机。可以的话根据状态转移函数自己推一下上面的表,这样会对自动机方法理解得更好。
自动机算法原理
通过状态转移函数,可以理解了有限自动机比朴素算法快在哪了。对于朴素算法,若字符不匹配则直接右移一位开始下一轮的m(模式P)个字符的比较。但是对于有限> 自动机来说,如果当前的字符不匹配(不能理想地进入下一个状态),自动机将根据转移函数δ回滚到之前已经匹配的某一个状态。这样的话即使字符不匹配也利用到了之前已经匹配的字符信息。例如对于上述的模式P=“ababaca”,如果已经有一个位移匹配到了前5个字符”ababa”,当下一个读入的字符是“c”则顺利地进入状态6。如果读入的字符是“b”,虽然不匹配(不是理想的“c”)但是根据状态转移函数我们只需回退到状态4。因为此时虽然不能凑齐6个字符匹配成功,但是我们任然能够凑齐4个字符匹配成功(“abab”)。如果读入的字符是”a”的话,那只能回退到状态1,既是只有1个字符匹配成功(“a”)。
代码实现
知道了如何计算状态转移函数(实际上就是知道如何根据一个字符串构造它的有限状态自动机),然后就可以通过扫描T找出所有匹配P的字符串了。具体看代码:
####根据状态转移函数ơ扫描T匹配字符串:
def finite_auto_matcher(T, f, m):
n = len(T)
q = 0
for i in range(0, n):
q = f[(q, T[i])]
if q == m:
print i+1-m
####构造状态转义函数:
def compute_transition_function(P, charSet):
f = dict()
m = len(P)
for q in range(0, m):
for a in charSet:
k = min(m, q+1)
while not ispostfix(P[:q]+a, P[:k]):
k -= 1
f[(q, a)] = k
for a in charSet:
f[(m, a)] = 0
return f
def ispostfix(s1, s2):
n = len(s1)
m = len(s2)
for i in range(0, m):
if s1[n-1-i] != s2[m-1-i]:
return False
else:
return True
算法实现复杂度
构造状态转义函数的时间复杂度是O(m^3 * | Ʃ |)。第14行循环m次,第15行循环| Ʃ |次,第18行最多执行m+1次,第17行的ispostfix函数最多m次比较。因此总共是m * m * m * | Ʃ | 。还有更好的算法可以使计算转移函数的时间降到O(m * | Ʃ |),因此对于有限自动机总的时间复杂度为O(n + m * | Ʃ |)。
4. kmp算法
相比于有限状态自动机,Kmp算法的优势在于它只需要O(m)的与处理时间,而有限状态自动机最快也需要O(m * | Ʃ |)。Kmp算法的主要思路跟字符串自动机很像,在预处理阶段建立一个前缀函数,然后顺序扫描文本T,即可找出所有与模式P相匹配的字符串。前缀函数与字符串自动机中的转移函数功能相同,都是当遇到匹配失败时能根据前缀函数(或者转移函数),利用之前匹配的信息,能够找出下一个应该匹配的位置,避免类似朴素算法做过多的无用功。
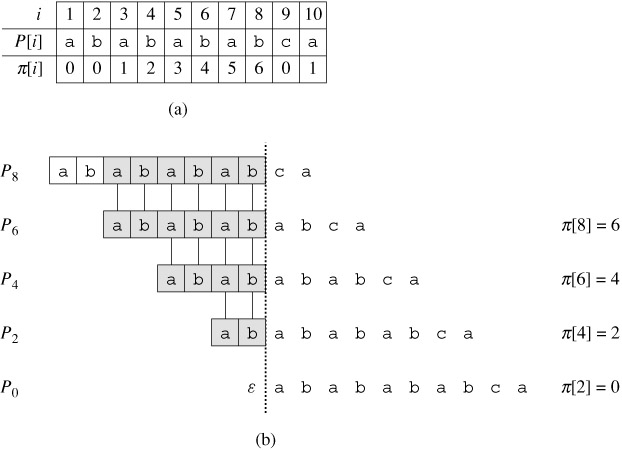{kind=link}
图片来自《算法导论》。看图(a),文本T和模式P一直匹配成功前5个字符,但是第6个字符不匹配。但观察可以发现此时已经匹配的5个字符中的后三个是模式P的前三个字符,因此我们可以退而求其次地将已经匹配的字符数减少一点,看能否匹配新的字符。如图(b),此时比较新的字符是否匹配P的第四个字符,这样的比较实际上是把P左移了2位。这个2是这样得来的,原来已经匹配了5位,这5位的后缀中在P的最长前缀(“aba”)的长度是3,5-3=2由此得出应该左移2位。
代码实现
我们先假设已经能够得到前缀函数,即是说先不去管前缀函数是如何计算出的。那当我们已经有方法得到前缀函数后,如何匹配模式P?看下面这段python代码,注意为了方便理解,我在字符串T、P前面都加上了一个空格字符,效果是模拟字符串下标从1开始而不是从0开始。
def kmp_matcher(T, P):
T = ' ' + T
P = ' ' + P
n = len(T) - 1
m = len(P) - 1
t = KMP.longest_prefix_suffix(P)
q = 0
for i in range(1, n+1):
while q > 0 and P[q+1] != T[i]:
q = t[q]
if P[q+1] == T[i]:
q += 1
if q == m:
print i-m+1
q = 0
代码分析
第6行调用函数longest_prefix_suffix,计算出模式P的前缀函数。第8行开始顺序扫描文本T,注意变量q记录此刻与模式P成功匹配的字符的个数。当下一个字符匹配失败时(P[q+1]!=T[i]),q的值根据前缀函数重新计算出,如9、10两行代码。当匹配成功时q的值只需简单加1。最后13行,当q的值(已经匹配的字符数)与模式P的长度相等时,我们便找到了一个匹配的字符串。
是时候来到最难理解的部分了(至少是我认为是最难理解的部分),计算前缀函数。其实如果不嫌慢的话可以暴力解法,但是时间复杂度是O(m^3),太差了。而书本给出的算法是O(m),对比产生美!
首先再说一下前缀函数的意思,前缀函数t[q]的物理意义是模式P的子串P[1..q]的后缀字符串中,是模式P的最大前缀的长度。
def longest_prefix_suffix(P):
if P[0] != ' ':
P = ' ' + P
m = len(P) - 1
t = [0] * (m+1)
k = 0
match = 0
for q in range(2, m+1):
while k > 0 and P[k+1] != P[q]:
k = t[k]
if P[k+1] == P[q]:
k += 1
t[q] = k
return t
一些理解
从代码上来看,计算前缀函数和匹配很相似,其实可以把计算前缀函数看作是和自己匹配的过程(书上这么说)。还是一样,为了数组下标从1开始,我把字符串下标0> 的位置放了一个空格。这段代码中变量k记录着当前匹配成功的字符的个数。11、12行代码是好理解的,当下一个字符匹配成功时,简单地把k加1。13行说的是,最后只需在下标为q的位置记录者子串P[1..q]的最长前缀数(k的值)。
对我来说,最难的部分在于理解9、10两行的代码,为什么当不匹配时只需不断的迭代(循环k = t[k]),便能找到适合的k值?
首先,发现对k不断地迭代(即k = t[k]),k的值会越来越小。回忆一下前缀函数的定义,t[q]表示P[1..q]的后缀,同时也是P的前缀的最大长度,所以其值显然要比q小。
所以有不等式:k > t[k] > t[t[k]] > ...
《算法导论》中有句话,通过对前缀函数的不断进行迭代,就能列举出P[1..q]的真后缀中的所有前缀P[1..k]。如果真如其所说的话,那么9、10两行代码就好理解了,当匹配失败时,从大至小地列举出其所有前缀,找到一个能使下一个字符匹配成功的前缀即可。而从大到小地列举出所有前缀只需要循环地迭代其前缀函数即可。因为我们已经得知前了,(1)缀函数不断迭代其值越来越小,(2)而且如书所说可以通过迭代来列举出所有可能的前缀。
好了,现在我们知道还剩哪里不懂了。就是为什么不断地迭代前缀函数能够列举出所有可能的前缀?现在整个KMP就只剩下这一部分的问题了,如果你不关心为什么你可以只是简单的记住这个结论。但是如果你想要具体了解为什么会得出这个结论,那你还得接着往下看,我们可以通过数学证明这个结论!
本站声明:网站内容来源于网络,如有侵权,请联系我们https://www.qiquanji.com,我们将及时处理。
微信扫码关注
更新实时通知