
RDF 和 SPARQL 初探:以维基数据为例
时间:5年前 阅读:6881
维基百科有一个姐妹项目,叫做"维基数据"(Wikidata)。你可以从维基百科左侧边栏点进去。
"维基数据"将维基百科的所有数据,整理成一个可以机器处理的数据库,方便查询。比如,山西省人口最多的地区是哪一个?
这种问题在维基百科查询,非常费时,必须人工从一个个条目提取信息。但是,维基数据可以只执行一条命令,就返回答案(详见后文)。因为它提供结构化数据,可以机器查询。
但是,维基数据不是关系型数据库,而是 RDF 数据库;查询语言不是 SQL,而是 SPARQL。我粗浅地学了一点 RDF 和 SPARQL,本文就是学习笔记,演示如何使用维基数据查询信息。

一、RDF 的含义
大家都知道,关系型数据库是目前使用最广泛的数据库,将数据抽象成行和列的表格关系。
但是,现实世界不像表格,更像网络。各种事物通过错综复杂的关系,连接在一起,组成一张网。
网络在数学里面称为图(graph),每样事物就是图的一个节点,节点之间的关系就是将它们连在一起的那条边。如果数据库以图的方式储存数据,就称为图数据库。
RDF 就是图数据库的一种描述方式,或者说是一种使用协议。它以"三元组"( triple)的方式,描述事物与事物之间的直接关系。
"三元组"是 RDF 的核心概念,指的是两个事物和它们之间的关系,在语法上呈现为"主语 + 谓语 + 宾语"。
天空是蓝色的。
上面这句话,就是一个 RDF 三元组。"天空"(主语)和"蓝色"(宾语)是两种事物,它们通过颜色关系(谓语)连接在一起。

RDF 要求,谓语(即事物之间的关系)必须有明确定义。大家这样想,如果谓语是给定的,就可以用主语去查询宾语,或者用宾语去查询主语。比如,颜色关系是给定的,那么就可以向数据库进行下面的查询。
查询一:天空 + 颜色 = ?
查询二:? + 颜色 = 蓝色
任何组织和个人,都可以定义自己的谓语。RDF 要求每套谓语必须有一个明确的 URL,通过 URL 区分不同的谓语。RDF 官方定义了一套常用的谓语,URL 如下。
https://www.w3.org/1999/02/22-rdf-syntax-ns
使用的时候,只要引用这个 URL,别人就知道用的是哪一套谓语。
URL 比较冗长,引用不方便。RDF 允许指定一个前缀,代表 URL 地址,比如上面那个官方谓语的 URL,通常用前缀rdf表示。
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns>
每个 URL 里面可以包含多种谓语,通过"前缀 : 谓语"的形式来区分。比如,官方定义了一个"type"谓语,说明主语的类型,就可以用rdf:type表示。
小明是学生。
上面这句话,写成 RDF 三元组,就是下面的形式。
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> 小明 rdf:type 学生.
由于rdf:type是一个常用谓语,RDF 允许把它简写成a,因此"小明是学生"又可以表示成小明 a 学生。
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns> 小明 a 学生 .
注意,每个 RDF 三元组的结尾是一个英文的句号,用来区分多个三元组。
二、 RDF 的语法示例
下面通过一个例子,演示 RDF 如何定义事物之间的关系。
甲壳虫是一个乐队,成员有 John Lennon、Paul McCartney、Ringo Starr 和George Harrison。他们都是艺术家,1963年出版过一张专辑《Please Please Me》,里面包含《Love Me Do》这首单曲,长度125秒。
上面这段话,是自然语言的文本。我们先画出网络关系图。
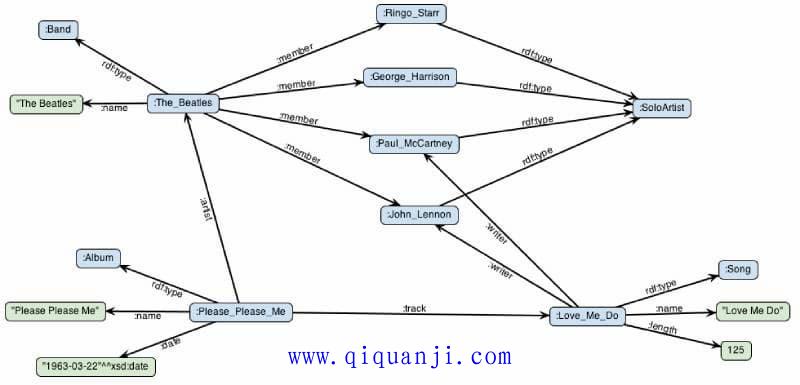
然后,转成 RDF 三元组。首先,给出谓语的 URL,及其对应的前缀。
PREFIX : <http://foo.com/tutorial/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns>
上面例子中,有两个 URL,表示使用两套谓语。其中一套是官方谓语,使用前缀rdf表示;另一套是自己定义的,前缀为空,表示这是默认的前缀。
"甲壳虫是一个乐队,成员有 John Lennon、Paul McCartney、Ringo Starr 和George Harrison。"这句话对应的三元组如下。
甲壳虫 rdf:type Band . 甲壳虫 :name "甲壳虫" . 甲壳虫 :member John_Lennon . 甲壳虫 :member Paul_McCartney . 甲壳虫 :member Ringo_Starr . 甲壳虫 :member George_Harrison .
上面例子中,rdf:type、:name、:member都是谓语。由于这些三元组的主语相同,RDF 允许将它们合并。
甲壳虫 a 乐队 ;
:name "甲壳虫" ;
:member John_Lennon, Paul_McCartney, George_Harrison, Ringo_Starr .
上面的代码中,主语相同的三元组采用合并写法时,每个三元组之间使用分号隔开,最后一个三元组采用句号结尾。
其余部分对应的 RDF 三元组如下。
John_Lennon a 艺术家 .
Paul_McCartney a 艺术家 .
Ringo_Starr a 艺术家 .
George_Harrison a 艺术家 .
Please_Please_Me a 专辑 ;
:name "Please Please Me" ;
:date "1963" ;
:artist "甲壳虫" ;
:track Love_Me_Do .
Love_Me_Do a Song ;
:name "Love Me Do" ;
:length 125 .
三、SPARQL 查询语言
SPARQL 是 RDF 数据库的查询语言,跟 SQL 的语法很像。它的核心思想是,根据给定的谓语动词,从三元组提取符合条件的主语或宾语。
SPARQL 查询的语法如下。
SELECT <variables>
WHERE {
<graph pattern>
}
上面代码中,<variables>是所要提取主语或宾语,<graph pattern>是所要查询的三元组模式。
比如,查询数据库里面的所有专辑。
SELECT ?album
WHERE {
?album rdf:type :Album .
}
上面代码中,?album是一个变量,名字可以随便起,第一个字符必须是问号?。查询的条件是,?album这个变量是主语,根据rdf:type这个谓语,可以得到:Album这个宾语。这个宾语也有前缀,表示这是当前数据库定义的。
如果返回的是符合条件的所有记录,变量可以用星号*代替,并且WHERE这个关键词在SELECT查询里面可以省略,最后一个三元组的结尾句号也可以省略,所以上面的查询也可以写成下面的样子。
SELECT * { ?album a :Album }
除了专辑名称,如果还要返回专辑的演唱者,可以增加一个变量?artist。
SELECT ?album ?artist
{
?album a :Album .
?album :artist ?artist .
}
上面代码中,?artist这个变量必须是?album(主语)和:artist(谓语)的宾语。
四、维基数据查询示例:山西省人口最多的地区
下面通过维基数据查询"山西省人口最多的是哪一个地区",进一步学习 SPARQL 语法。
首先,进入维基数据网站,在页面顶部的搜索栏,搜索"山西"。或者,维基百科的"山西省"页面,左边栏也有跳转到维基数据的链接。
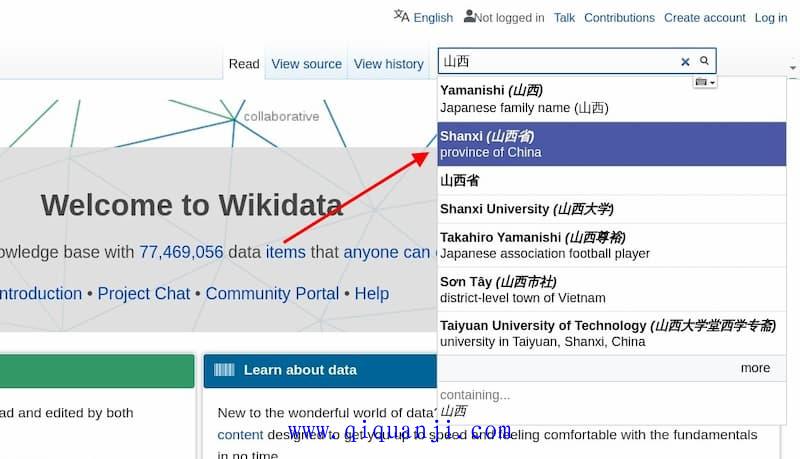
然后,进入山西省的页面。
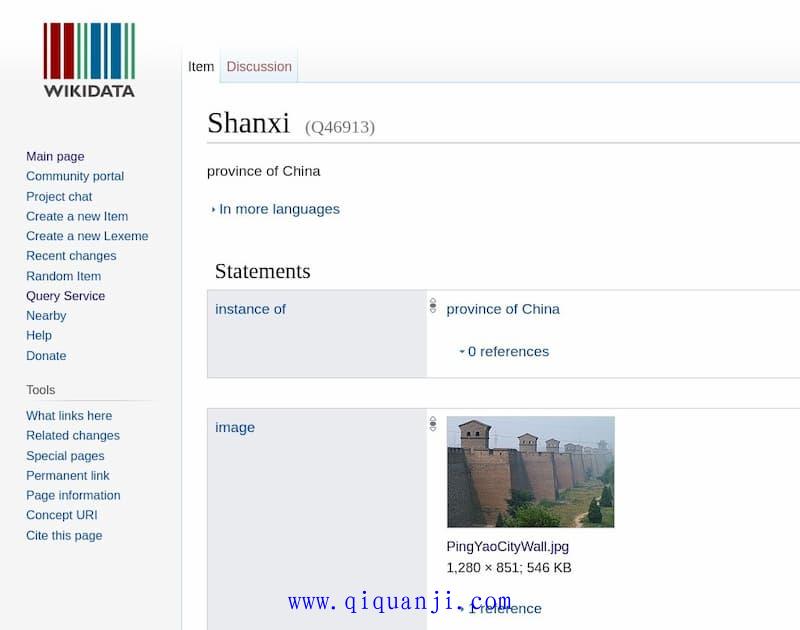
这时,留意一下这个页面的 URL。
https://www.wikidata.org/wiki/Q46913
上面 URL 最后结尾的Q46913,就是山西省这个条目在维基数据的编号(即主语),后面要用到。
接着,页面向下滚动,找到"contains administrative territorial entity"(所包含的行政实体)这个部分,它列出了山西省下辖的各个地区。
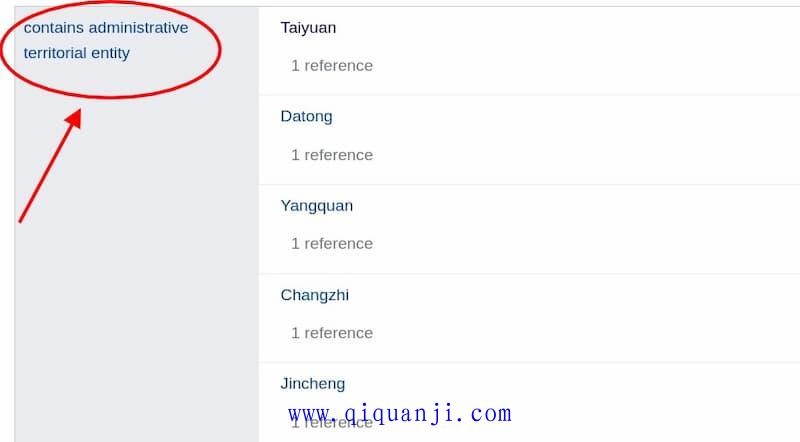
点击"contains administrative territorial entity"这个标题,进入它的页面,也留意一下 URL。
https://www.wikidata.org/wiki/Property:P150
上面 URL 的最后部分P150,就是"所包含的行政实体"这个谓语动词的编号。
现在,就可以开始查询了。进入维基数据的在线查询页面 query.wikidata.org
在查询框里面,输入下面的 SPARQL 语句。
SELECT ?area
WHERE {
wd:Q46913 wdt:P150 ?area .
}
上面代码要求返回变量?area,该变量必须满足主语"山西省"(wd:Q46913)和谓语"所包含的行政实体"(wdt:P150)。前缀wd表示这是维基数据的条目,而前缀wdt表示这是维基数据定义的谓语关系。
点击左侧边栏的三角形运行按钮,就可以在页面下方得到查询的结果。

从上图可以看到,返回的都是条目的编号。修改一下查询语句,增加一栏文字标签。
SELECT
?area
?areaLabel
WHERE {
wd:Q46913 wdt:P150 ?area .
?area rdfs:label ?areaLabel .
FILTER(LANGMATCHES(LANG(?areaLabel), "zh-CN"))
}
上面代码中,增加了一个返回的变量?areaLabel,该变量是前一个变量?area的文字标签(满足谓语rdfs:label),同时增加了一个过滤语句FILTER,要求只返回中文标签。
运行这段查询,就可以看到每个地区的中文名字了。
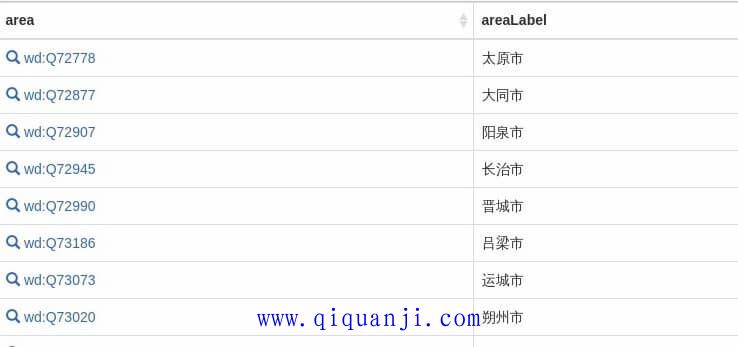
接着,再增加一个人口变量?popTotal,返回每个地区的人口总数。
SELECT
?area
?areaLabel
?popTotal
WHERE {
wd:Q46913 wdt:P150 ?area .
?area rdfs:label ?areaLabel .
FILTER(LANGMATCHES(LANG(?areaLabel), "zh-CN"))
?area wdt:P1082 ?popTotal .
}
运行这段代码,就可以看到人口总数了。
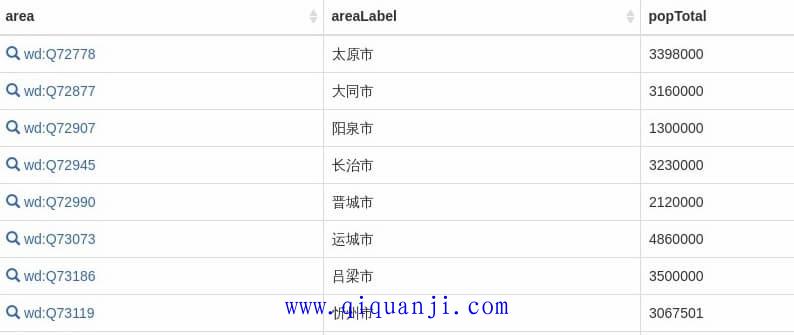
然后,增加一个排序子句order by,按照人口的倒序排序。
SELECT
?area
?areaLabel
?popTotal
WHERE {
wd:Q46913 wdt:P150 ?area .
?area rdfs:label ?areaLabel .
FILTER(LANGMATCHES(LANG(?areaLabel), "zh-CN"))
?area wdt:P1082 ?popTotal .
}
ORDER BY desc(?popTotal)
运行结果如下。

最后,加上一个limit 1子句,只返回第一条数据。
SELECT
?area
?areaLabel
?popTotal
WHERE {
wd:Q46913 wdt:P150 ?area .
?area rdfs:label ?areaLabel .
FILTER(LANGMATCHES(LANG(?areaLabel), "zh-CN"))
?area wdt:P1082 ?popTotal .
}
ORDER BY desc(?popTotal)
limit 1

这样就得到了山西省人口最多的地区。
五、维基数据查询示例:程序员名录
下面再看一个例子,找出维基百科收入的所有程序员。
SELECT
?programmer
?programmerLabel
WHERE {
?programmer wdt:P106 wd:Q5482740 .
?programmer rdfs:label ?programmerLabel .
FILTER (LANGMATCHES(LANG(?programmerLabel), "zh-CN"))
}
上面代码中,Q5482740 是程序员,P106 是职业。
运行这个查询,就可以看到程序员名单了。
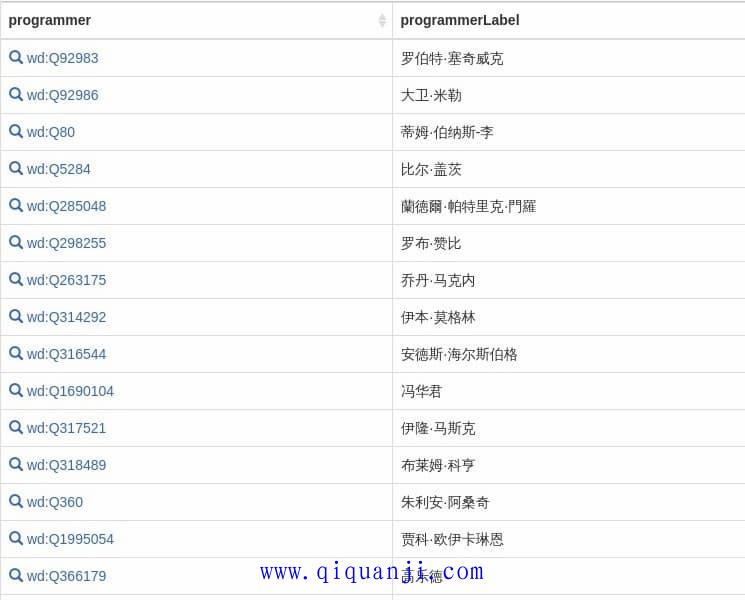
注意,这里只返回有中文名的程序员。如果数据库里面没有收入程序员的中文名,这里就不会返回。
然后,查询每个程序员的主要成就。
SELECT
?programmer
?programmerLabel
?notableworkLabel
WHERE {
?programmer wdt:P106 wd:Q5482740 .
?programmer rdfs:label ?programmerLabel .
FILTER (LANGMATCHES(LANG(?programmerLabel), "zh-CN"))
?programmer wdt:P800 ?notablework .
?notablework rdfs:label ?notableworkLabel .
FILTER(LANGMATCHES(LANG(?notableworkLabel), "zh-CN"))
}
运行结果如下。

有的程序员有多项成就,比如,约翰·卡马克有"毁灭战士"和"雷神之锤"两项成就。这时可以用GROUP BY子句将它们合并在一起。
SELECT
?programmer
?programmerLabel
(GROUP_CONCAT(?notableworkLabel; separator="; ") AS ?works)
WHERE {
?programmer wdt:P106 wd:Q5482740 .
?programmer rdfs:label ?programmerLabel .
FILTER(LANGMATCHES(LANG(?programmerLabel), "zh-CN"))
?programmer wdt:P800 ?notablework .
?notablework rdfs:label ?notableworkLabel .
FILTER (LANGMATCHES(LANG(?notableworkLabel), "zh-CN"))
}
GROUP BY ?programmer ?programmerLabel
上面代码中,GROUP_CONCAT函数用来把多个?notableworkLabel变量合并成新的一栏works。
运行结果如下。

上面图片中,"毁灭战士"和"雷神之锤"已经合并成一个单元格了。
接着,为每个人增加一个头像照片。
SELECT
?programmer
?programmerLabel
(GROUP_CONCAT(?notableworkLabel; separator="; ") AS ?works)
?image
WHERE {
?programmer wdt:P106 wd:Q5482740 .
?programmer rdfs:label ?programmerLabel .
FILTER(LANGMATCHES ( LANG ( ?programmerLabel ), "zh-CN"))
?programmer wdt:P800 ?notablework .
?notablework rdfs:label ?notableworkLabel .
FILTER (LANGMATCHES ( LANG ( ?notableworkLabel ), "zh-CN"))
OPTIONAL {?programmer wdt:P18 ?image}
}
GROUP BY ?programmer ?programmerLabel ?image
上面代码中,返回值增加了一个照片变量?image。由于不是每个人都有照片,所以把照片要求放在OPTIONAL条件中,表示这一项是可选的。
得到查询结果后,把结果的表格视图(table)切换成图像视图(image grid)。
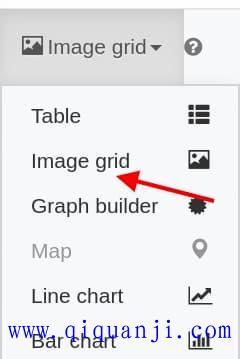
这时,照片就可以显示出来了。

最后,我们想知道他们是哪个地方的人,维基数据提供他们的出生地。
SELECT ?programmer
?programmerLabel
(GROUP_CONCAT(?notableworkLabel; separator="; ") AS ?works)
?image
?cood
WHERE {
?programmer wdt:P106 wd:Q5482740 .
?programmer rdfs:label ?programmerLabel .
FILTER(LANGMATCHES ( LANG ( ?programmerLabel ), "zh-CN"))
?programmer wdt:P800 ?notablework .
?notablework rdfs:label ?notableworkLabel .
FILTER (LANGMATCHES ( LANG ( ?notableworkLabel ), "zh-CN"))
OPTIONAL {?programmer wdt:P18 ?image}
OPTIONAL {
?programmer wdt:P19 ?birthplace .
?birthplace wdt:P625 ?cood .
}
}
GROUP BY ?programmer ?programmerLabel ?image ?cood
上面代码中,返回值增加了坐标变量cood,先查询程序员的出生地,然后查询出生地的地理坐标。
运行查询之后,默认的表格视图就会出现坐标。
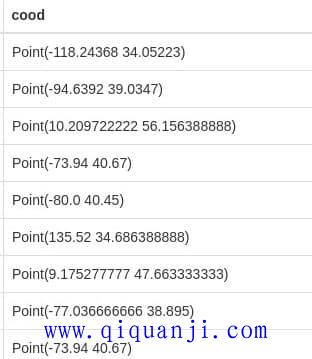
把视图切换成地图(map)。
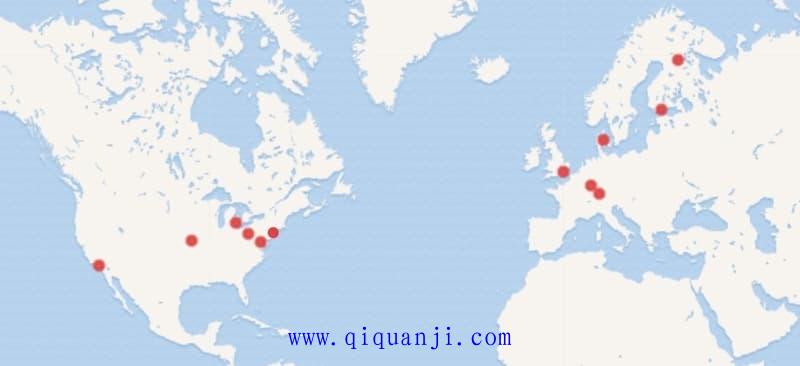
这时就能看到这些程序员在世界地图上的位置。
这篇教程就到这里为止,维基数据的查询方法还有很多,继续学习可以点击查询页头部的Examples按钮,看看官方提供的示例。
六、参考链接
- RDF, Wikipedia
- RDF Graph Data Model, Stardog
- Learn SPARQL, Stardog
- SPARQL Nuts & Bolts, Cambridge Semantics
- How to Extract Knowledge from Wikipedia, Data Science Style, Michael Li
本站声明:网站内容来源于网络,如有侵权,请联系我们https://www.qiquanji.com,我们将及时处理。

微信扫码关注
更新实时通知
网友评论